

Table of contents
Research teams are sitting on goldmines of unstructured consumer data – social media posts, product reviews, forum discussions – but struggle to extract meaningful insights at scale.
Traditional qual and quant research methods provide unmatched depth, but require significant time and resources. Out-of-the-box generative AI tools can’t reliably quantify or size topics. Topic modelling bridges this gap, combining analytical rigour with speed and efficiency.
This blog explains what analysing unstructured data can do for your strategy, our powerful five-step topic modelling process for understanding real consumer behaviour, and when topic modelling is the ideal approach for your research needs. You’ll also learn how our toolkit differs from other AI-based methods and generative AI tools.
How does topic modelling work in market research?
Topic modelling is a technique that identifies key themes within large datasets of unstructured content – such as social media posts, product reviews, forum discussions, articles and images – and labels that data accordingly. Most relevant online data is unstructured, which makes it particularly challenging to work with. Traditionally, topic modelling was used to mine text, but with current computer vision algorithms, we can now apply it to images too.
In market research, this means transforming millions of consumer conversations into structured, quantifiable insights that directly inform business strategy.
Benefits of analysing unstructured data
The internet holds a vast wealth of consumer-generated data with the potential to massively benefit businesses’ strategies – if it can be successfully distilled into actionable insights.
When it comes to business questions that can be answered with online data, our unstructured data analysis toolkit offers a much more efficient alternative:
Core benefits of analysing unstructured data with our toolkit:
- Access at scale – Find and assess billions of real, public online conversations through APIs (Application Programming Interfaces – the systems that let different software communicate) and proprietary scrapers, in almost any country and language.
- Speed and cost efficiency – Gain valuable insights in just a few weeks, and for a relatively low cost.
- Objective quantification – Measure and size topics in ways that can’t be achieved with Generative AI assistant tools (e.g. Deep Researcher Agents) alone.
- Real consumer language – Draw a more accurate picture of consumer journeys by examining what buyers post before and after major purchase decisions.
- Hypothesis testing – Test assumptions and build category understanding before (or instead of) committing to primary research.
Our 5-step topic modelling process
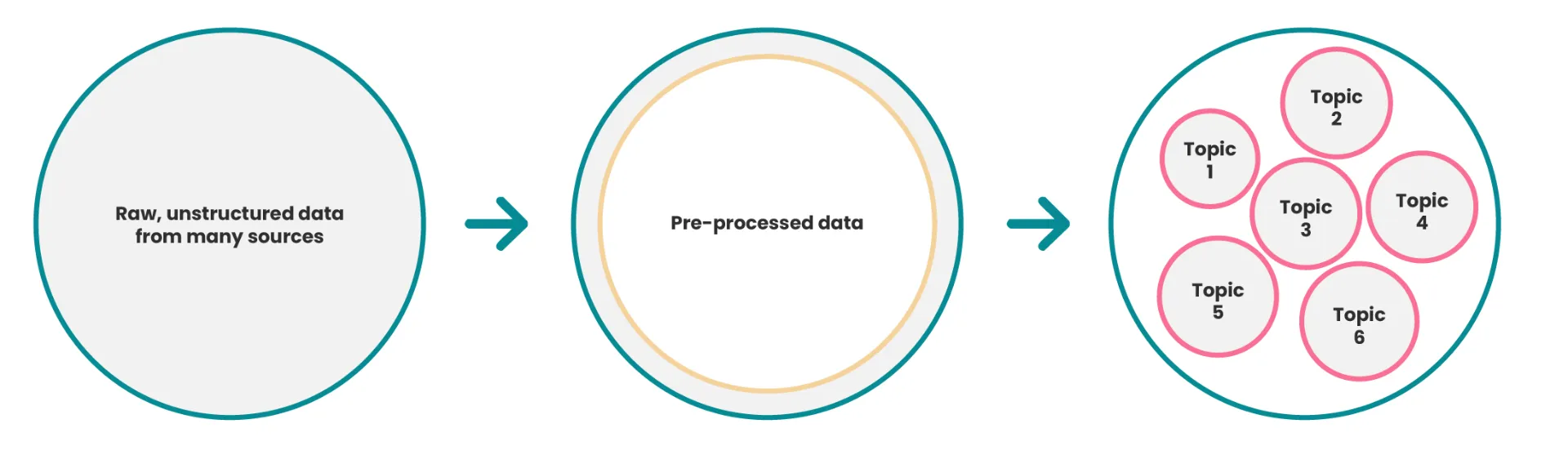
At STRAT7 Bonamy Finch, our toolkit has been honed from our experience over the past 5 years and offers a clear step by step process which provides powerful insights quickly.
STEP 1: Defining the right business questions
In the kickoff phase, we work with clients to break down broader business questions into several focused, testable hypotheses that can be answered by the data.
The questions best suited to topic modelling can be answered by sizing topics and tracking changes over time. For example, “Why have our sales changed by X amount over the past three years?” would be broken down into testable hypotheses like:
- “The share of voice for our brand has changed significantly in this period.”
- “The perceived importance of customer service has increased in this period.”
Often these are hypotheses clients already have and want to test, but we can also suggest new ones based on our analysis of the data.
STEP 2: Collecting high-quality unstructured data

The next step of the process involves collecting the unstructured data at scale, usually via scraping the web. It’s crucial to get this step right, as with any statistical technique, the “rubbish in, rubbish out” rule applies here as well.
Unstructured data is both vast (the entire public internet), and hugely variable in quality. We prioritise working with clients to identify the most relevant data sources for their business question. We can build bespoke web scrapers to target these sources, like specialist websites that aren’t covered by social listening platforms. We can also specify extra constraints on the data collection, like which competitor brands and what markets to collect data on, what types of data (e.g. forum posts, social media, news articles, and so on) are in scope, etc.
STEP 3: Processing data for accuracy and insight
We carefully clean and process the data we collect to ensure only relevant, high-quality verbatims (the raw text from consumer posts and comments) get analysed.
This means removing duplicate posts, low-quality content, advertisements, and posts from brand accounts or businesses (where applicable). We also break down longer pieces of content at paragraph or sentence level, so topics can be assigned more precisely.
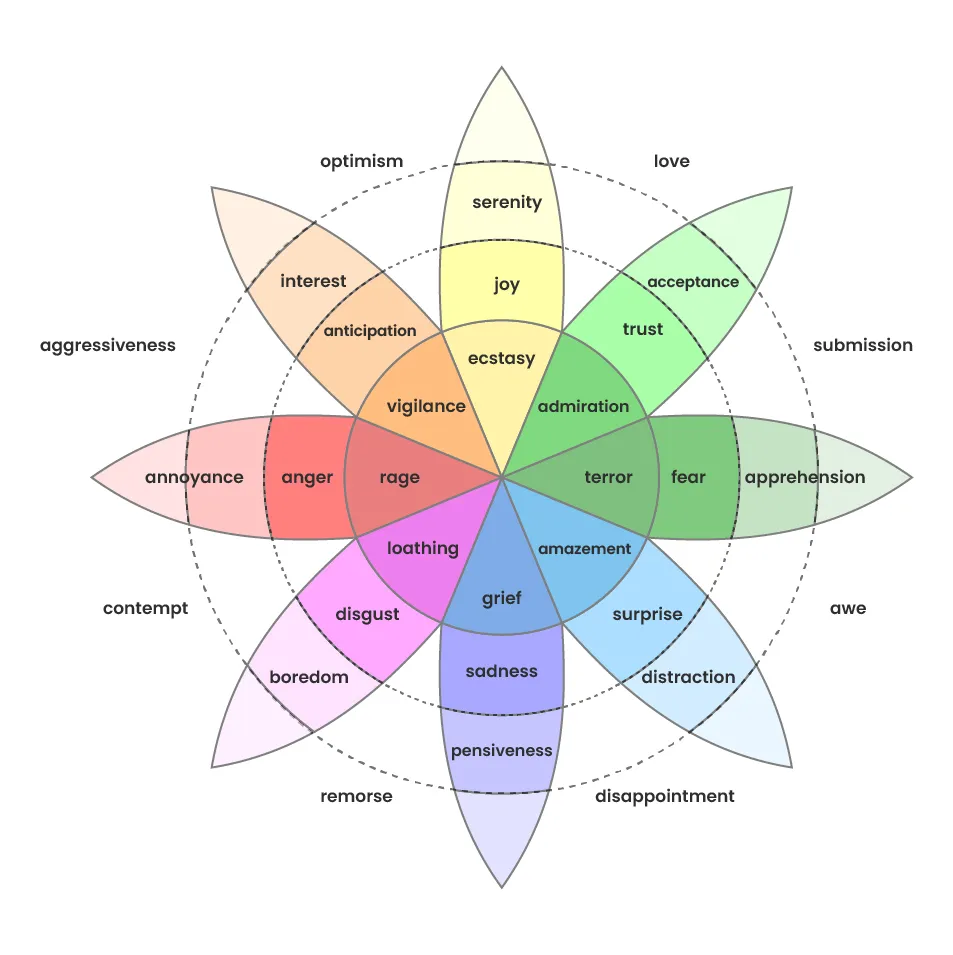
Finally, we run the data through our in-house sentiment and emotion detection algorithms. This tags each data point with a sentiment label (Positive, Negative or Neutral) and an emotion label (one of nine emotions based on Plutchik’s emotion framework, see diagram). These layers of analysis help us understand not just what people are talking about, but how they feel about it.
STEP 4: Building transparent and replicable topic models
We use a combination of traditional text analytics and state-of-the-art methods to precisely identify the key topics of conversation. This includes word embedding (a way of representing words as numbers that capture their meaning and relationships) and LLM-based techniques.
Once we’ve finalised the list of topics, we create the topic models. These are typically codified as rule-based algorithms using specific words and subwords.
This approach has two major advantages:
- The topic definitions are fully transparent
- The assignment is rule-based, so we can run the same model on updated datasets to provide comparable results over time. This is particularly valuable for AI-based trackers, where we monitor how topics evolve with each new wave of data.
STEP 5: Turning insights into actionable strategies
By this stage, the unstructured online data has been transformed into a high-quality, structured dataset suitable for undergoing quantitative analysis. We connect key metrics – such as share of voice or topic penetration – directly to the client’s strategic objectives.
We work with experts across STRAT7’s ecosystem to integrate our findings with primary research data and desk research. The result is a clear, actionable report that directly answers the “So what?” question. The analysis and reporting is fully bespoke and done by humans. Currently no AI can replace the rigorous thinking and years of experience required to turn raw data into strategic recommendations.

When topic modelling isn’t the right approach
Topic modelling is a powerful technique for quantifying and structuring online data. However, it’s not suitable for every business question about online data. When there’s no need to size topics, or when questions are more qualitative in nature, other tools may be more appropriate.
For quick insights without quantitative analysis, deep research tools launched earlier this year (like Perplexity or Open AI’s Deep Researcher) can be useful. We’ve also launched our own versions of these tools at STRAT7 (including one called Crowd Tracks), as we recognised that there’s a need for a variety of approaches to answer different use cases.
Finally, conventional social listening tools can be more appropriate for setting up self-serve dashboards with simple analysis capabilities.
STRAT7 Bonamy Finch’s toolkit:
Topic modelling vs other AI methods
Different tools excel at different tasks. While conventional social listening platforms are ideal for daily brand monitoring and self-serve dashboards, and deep research tools offer quick qualitative insights, our topic modelling toolkit is purpose-built for quantitative analysis and strategic depth.
What sets our toolkit apart? We combine comprehensive data access with rigorous cleaning processes, advanced analytical techniques (including emotion detection and image analytics), and most importantly, expert consulting to translate findings into strategies aligned with your core business objectives. Where other tools stop at identifying themes, we quantify them, track them over time, and connect them directly to actionable recommendations.
How to get started with topic modelling
At STRAT7, our AI design principles put business problems first. We identify the challenge you’re facing, then deploy the right toolkit to solve it. Topic modelling is a flexible and powerful tool for many research projects, but whether it’s the right fit depends entirely on your specific requirements.
See how we’ve helped our clients address their challenges. View our client work here.
If you’d like to explore how this toolkit can help your business, please contact us.
Mihaela joined STRAT7 in early 2024, after completing a PhD in computational biochemistry and a brief stint as a data engineer. As a data scientist at STRAT7 Bonamy Finch, she works on applying machine learning and AI tools to answer market research questions, with a focus on unstructured data.