
Our segmentation chatbot is a new STRAT7 tool which allows users to access and communicate with segmentation data in a natural language style. It helps with summarising, creating content, fact finding and providing strategic opinions.
By applying advanced AI search retrieval methods to traditional market research outputs, it provides accurate and creative responses to user questions.
This saves time by reducing requests for busy insights teams, democratising the segmentations by making the findings accessible to all, and enabling faster decision-making. Overall, the chatbot increases organisational engagement with segmentations, maximising their lifetime value and increasing their return on investment.
Our first blog explained the benefits of the product for our clients. We now turn our attention to the technical detail underpinning the tool, including the data science techniques we’ve used over the past few months.
Two modes of operation
Our segmentation chatbot is designed to handle two primary types of questions: numeric and contextual.
Numeric questions seek specific answers, such as “What is the size of Segment X?” or “What is the average age of Segment X?”
Contextual questions on the other hand, aim to provide summaries, insights, and comparisons between different segments, and answer queries such as “Give a brief overview of Segment X” or “How does Segment X compare to others in terms of targeting and innovations?” or “Which segment will be most interested in a new Italian restaurant opening in their area?”
To ensure precise and relevant answers to both types of questions, we have created two separate modes within the chatbot: numeric and contextual, accessible via a drop-down menu for users. The numeric mode is optimised to provide exact, data-driven responses using only numeric data tables. The contextual mode leverages other project documents (except data tables) to offer more nuanced, creative insights.
Contextual mode
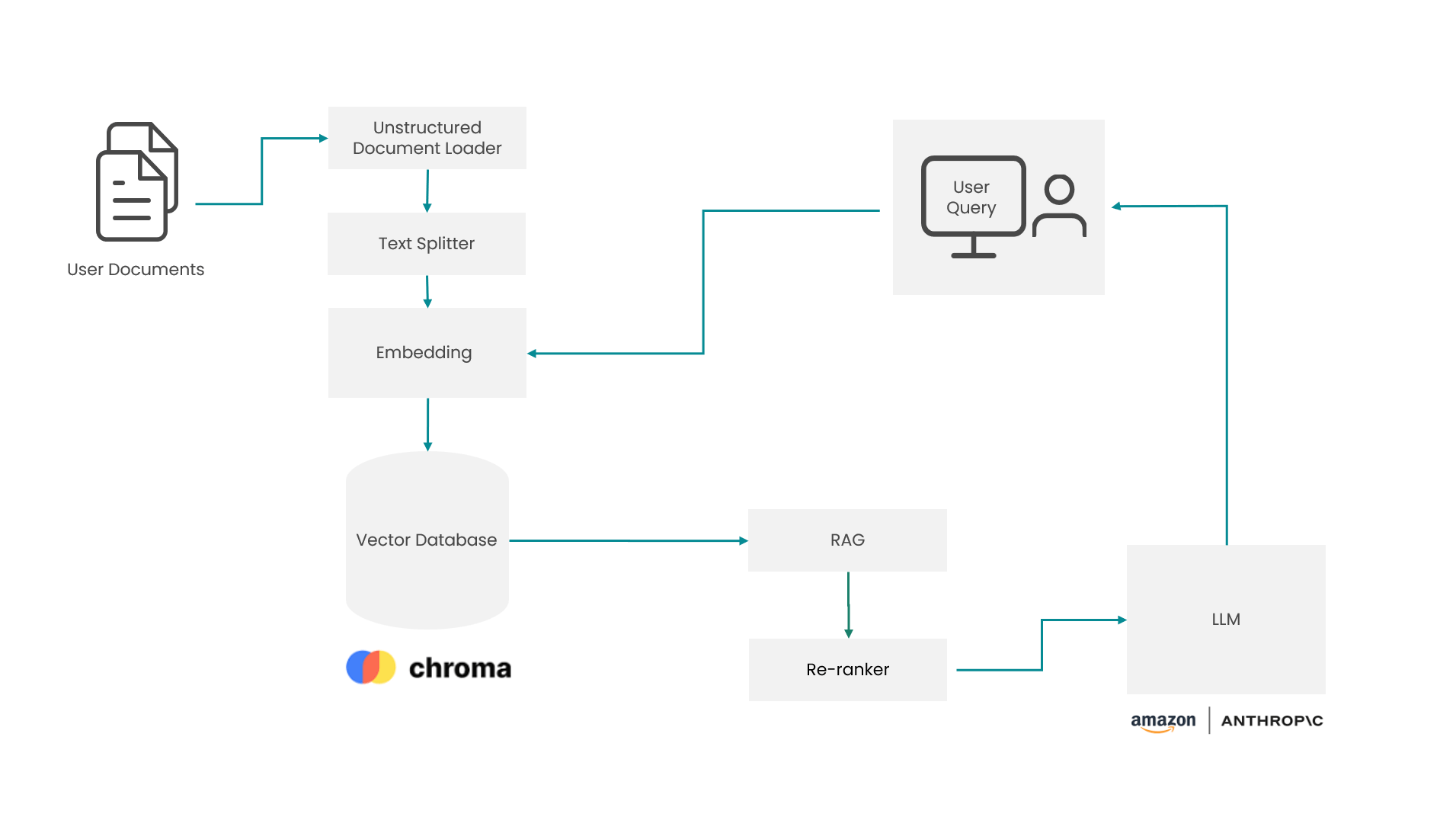
In contextual mode, we handle documents such as PDFs, PPTs, and DOCs using off-the-shelf unstructured document loaders. Extracted information is split into chunks, vectorised, and stored in a vector database. For some of the document types, like PowerPoint, we added a pre-processing step where the text from tables is extracted and formatted in such a way that the model can understand the relationship between rows and columns. After that the text is injected back into the document.
One of the most important features of the segment chatbot is its transparency. We aimed at showing the parts of the documents where the data is taken from when answering to the user queries. After the LLM generates a response, a list of the most relevant document pieces is shown with links to each one of them. These links point to the specific page/slide of the underlying document. In this way, the users can immediately check the response and quickly get additional context.
RAG and re-ranking
To deliver the most relevant context to the LLM, we apply a two-step process involving a RAG (retrieval augmented generation) search followed by re-ranking:
1. Apply RAG search that returns a bigger number of documents/chunks (~50-100) and then…
2. These chunks are fed into a re-ranker algorithm that scores each of the documents against the user query and return a smaller set (Top N) in a descending order of their scores. The scores show the similarity between the query and the chunk contents. The higher the score the more relevant the chunk is to the given question.
This two-step approach ensures the chatbot uses the most pertinent chunks of data to respond to user queries accurately (see diagram below).
For reference, a good explanation of the algorithms can be found here.
Numeric mode
A large portion of segmentation data is stored in tabular format, so we had to make sure that the chatbot could accurately and robustly respond to questions about these tables.
LLMs (in)famously struggle to understand numbers, particularly when the task also involves incorporating numerical data into a human-like response.
Because of this, we deliberately chose a fast and lightweight language model, both in terms of user experience (faster response times) and cost.
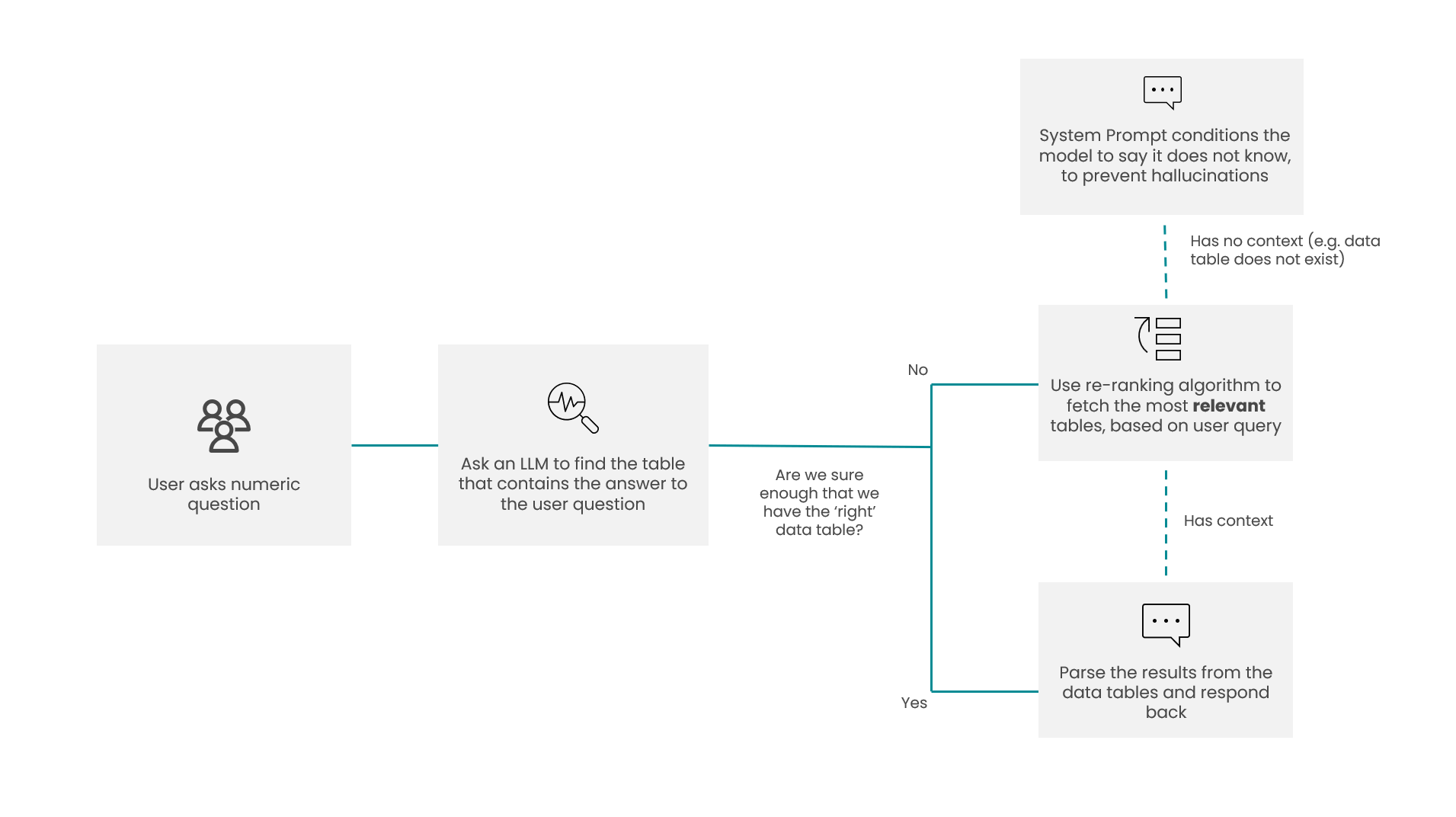
The underlying idea is for the chatbot to quickly and accurately retrieve the relevant tables and variables that the user should investigate further. Unlike contextual mode, where the app has access to high quality written information on the segmentation (reports, pen portraits, transcripts), numeric mode is all about pointing the user to the key parts of the underlying data without offering additional interpretation.
For the user, this removes the cognitive load of switching between data dictionaries and summary tables, allowing quick interaction with the data without breaking their flow and letting them fully concentrate on the analysis and underlying questions.
In a similar vein to contextual mode, we’ve created a bespoke process that can find the most relevant data table to any user query (see diagram below).
Hurdles to overcome
To get to the point where the LLM reliably returns accurate answers based on the tables, we had to overcome the following:
1. Hallucinations
A well-known problem for LLMs, these are particularly dangerous for our application, as user trust in the app’s response is paramount.
Steps we took to address this:
– Lower the temperature settings of the model (to be as factual as possible).
– Custom system prompts for numeric mode. These instruct the model to show all relevant data without making judgements or providing further analysis. The model is also prompted to concisely explain the variables and values in the response and how they relate to the question. In the system prompt, we also explained some segmentation-specific terminology to the model and reiterated the importance of only including information present in the context documents.
– Show underlying sources for each answer with table titles and hyperlinks to the relevant file/Excel sheet. This allows the user to immediately fact-check the response. For example, if the source table titles are not related to the question, or if the answer references a table title that is not shown as a source, the model is likely to have hallucinated. If the sources seem relevant to the question, the user can quickly navigate to the underlying data to fact-check the LLM’s response, or to explore the data further.
2. Retrieving the correct tables/ variables
When we used the standard chunking and RAG retrieval for textual information, we found that (particularly for longer tables) some relevant chunks may not be retrieved at all (for example, a chunk from the end of a table that misses the header).
Steps we took to address this:
– Introduce an additional step for pre-selecting relevant tables. Instead of performing RAG on all chunks in the vectorstore based on cosine similarity alone, we first provide the LLM with a list of table titles and descriptions and prompt it to select tables that are relevant to the user’s question. Chunks from each table are then retrieved through the RAG-rerank flow described above.
– Display tables together in the context. Longer tables may be split into several chunks in the vectorstore. When these chunks are retrieved and re-ranked, the context (not the LLM’s context!) may be lost. This is especially problematic for questions that ask about values for all segments, or values for all statements within a table, and result in the model giving a partial (and incorrect) reply based on the subset of data it sees, or even merge information from different tables together.
– Keep variable names and descriptions close together when creating the chunks. This helps the model identify relevant variables when crafting its response (same as a human may lose focus when mapping variable names to descriptions).
3. Correct numbers are retrieved in the context, but LLM response is incorrect
This came up a lot when we ask questions that involve summarising numeric data, such as ‘Which is the largest segment’, or ‘List all segments that have more males than females’. The LLM may even include the correct numbers in its response, yet confidently state that ‘As is clearly evidenced in the data, Segment X is the largest with a value of 15.6, closely followed by Segment Y with a value of 300.0’.
Steps we took to address this:
– Show the data, omit the interpretation. We prompt the model to show all data in the underlying tables that can answer the question, but not attempt to answer the question directly. The response also shows the titles (and hyperlinks to) the relevant tables, so the user can fact-check and interact with the data directly. This way, the model does the ‘grunt work’ of retrieving and showing the data, but the analysis and interpretation is still in the hands of the human.
– Do not pass raw survey data to the model. Input summary statistics on a segment level. We do not include any individual-level data, as that is not relevant and the model is not equipped to actually run a segmentation.
– Pay attention to significant figures: Segment X has an index of 115.1293781273821738237821’ is clearly too much information. However, directly parsing the tables and converting floats to strings will send these number representations to the LLM. While we could instruct the model to round numbers in its response, we instead chose to round the numbers in the underlying data. This both sends fewer tokens overall, reducing costs, and helps the model focus on the relevant numbers, not the noise tokens.

Testing
Getting to the set of prompts, workflows, and parameters that make up the segment chatbot is an iterative process with many moving parts.
Optimising the app can feel like a bit of a ‘whack-a-mole’, where modifications that improve performance on some types of tasks will worsen performance on others. It is important to be able to quickly test many configurations and assess their overall performance in an objective way. To do this, we compiled a diverse set of questions and expected answers based on the underlying data, mimicking the types of questions that users would be most interested in.
We consulted internal STRAT7 experts with years of experience in delivering and deploying segmentations, which was hugely helpful to identify the set of tasks that we needed to optimise performance on. Another key aspect of the automated tests was including questions on data that is not in the context and making sure the model does not hallucinate.
This methodology was crucial for developing numeric mode, where the questions have clear answers in the data. In contextual mode, however, multiple valid answers could be possible (for example ‘What is a four-course set menu that Segment Y would enjoy?’). Here, we heavily relied on user feedback from our internal experts and their wealth of know-how.
The testing phase also included external assessment. We asked one of our clients to test the segment chatbot and give us feedback. The response was very positive with lots of enthusiasm to apply the tool in their daily activities.
Next steps
While we’ve made significant strides in building our segmentation chatbot tool, it should be noted that we have ruled out using a couple of approaches, even though they may be useful in other Generative AI tools.
For example, we could have gone down the route of executing Python code to handle numeric questions, rather than instructing the chatbot to only retrieve and present numeric data. In our hands, this slowed down the response times, and took control away from the user (many users interested in numeric questions want to see the underlying data and double check the response).
The chatbot also currently only handles text and numeric data. A future possibility would be to use the multimodal capabilities of the newer models to also ‘look at’ ads or images. For example, one could upload a draft of a social media post and ask the chatbot whether it would appeal to a particular segment.
We’re constantly updating the underlying components and architecture to take advantage of the newest advancements in the field.
It’s been a very exciting journey so far, and we look forward to exploring further the interplay between market research and AI technology.
For more information about our segmentation chatbot please get in touch, or contact Hasdeep Sethi directly at hasdeep.sethi@bonamyfinch.com.