

Hasdeep Sethi, Data Science Director at Bonamy Finch and strat7.ai Data Science Lead, played a big role in helping us launch a secure generative AI tool for use by all consultants across the STRAT7 group. Here’s what he learned along the way.
Back in June, the STRAT7 group made a commitment to invest further into our strat7.ai capabilities, to help democratise the benefits of new Generative AI technologies.
The many benefits are well documented and are poised to help make our staff more productive, create more headspace for unlocking strategic insights, and develop new solutions for our clients.
As a Data Scientist turned part-time Product Owner, here are 10 key learnings from building and releasing our first internal Generative AI product – strat7GPT.
1. Start with a focused use case
With new developments coming thick and fast in the Generative AI space, it can be challenging to know where to start when looking to build solutions that help colleagues and clients. At STRAT7, we turned to the whole business to get started – asking them about their pain points and sending out surveys to ask them to prioritise use cases.
The largest need identified (by far) was to summarise documents quickly and securely. This could range from summarising 10 anonymised transcripts, understanding the high level themes in 500 survey open ends or helping someone on-boarding mid-way through a project with sifting through various documents and written materials. All done in minutes what could (until 2023) take several hours.
This has set in motion the vision for strat7GPT, as a tool to synthesise and pull out key insights from any source of unstructured data. By starting narrow, we are then able to widen out the use of strat7GPT across other important use cases.
2. Build a niche
We have deliberately built a product that solves a need and has a niche. While closed source models are useful, and we have developed materials to help our colleagues use these tools, the free versions are often not as secure from a data privacy perspective. They can also be limited to ‘copy and pasting’ from documents to give more context, which makes retrieval augmented generation (RAG) search a tedious task.
At the same time, we have an AI powered research methodology – strat7.ai – which goes much further than strat7GPT’s current capabilities. So strat7GPT sits between the two, as can be seen in the comparison table below:
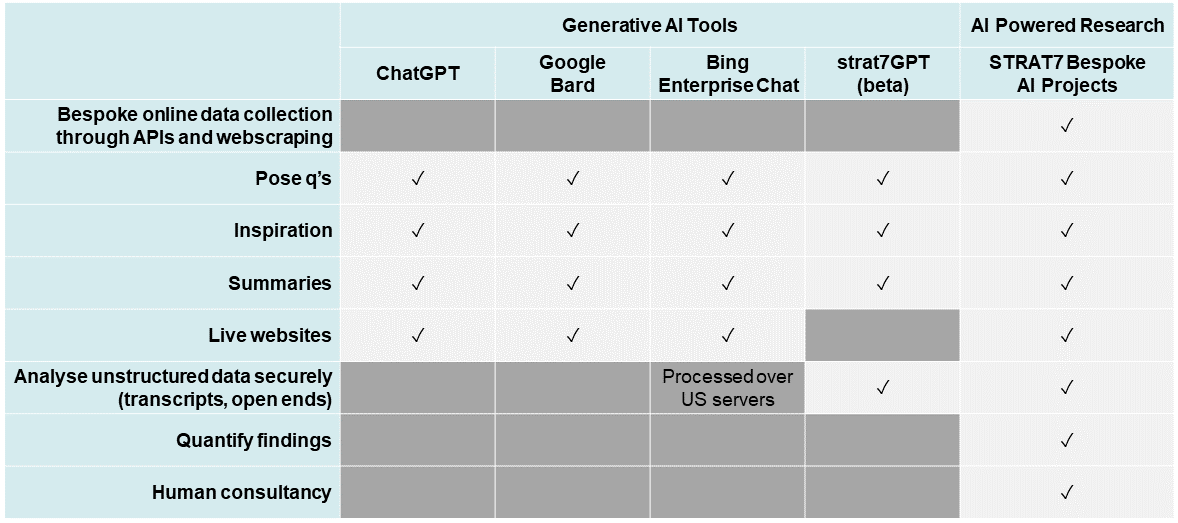
Comparison table. Accurate as of November 2023.
3. Start small and then go big
The strat7GPT tool currently uses open-source models – securely deployed from our cloud platform – to power the application.
To start with, we consciously chose ‘smaller’ parameter LLMs (Large Language Models) which are cheaper to host and deploy, allowing us to quickly get the application in the hands of users, in true agile fashion.
While we could have played ‘the waiting game’ until more enterprise secure tools are made available, we decided to go ahead with the best performing open source models that wouldn’t break the bank, meet our data privacy obligations and use a test and learn framework to improve things.
After gathering in-app user feedback, we are now delivering on a roadmap to include much larger models, which can handle bigger swathes of text as inputs. This includes scope to fine tune the current models for specialist tasks, including teaching the models the jargon that our STRAT7 agencies use for more refined outputs.
4. Be prepared to pivot and pivot again
The nature of building a Generative AI application means that we’re operating in an environment where new technological developments and best practice are changing literally week by week.
We have been pragmatic since Day 1. Pivoting to take advantage of new information instead of committing to a defined solution by a fixed end date. While this may sound like an obvious approach, it can be tempting to commit to a solution and then go through a standard agile software build and release cycle.
But with Generative AI, we’ve found the solution itself and underlying technology also needs to be flexible enough to keep pivoting in a changing landscape.
5. Disseminate the art of prompting
It’s well known that crafting prompts to elicit the right information from these models is not just a nice to have, but an essential part of the process. Even with the best performing LLMs, they need to be talked to in a certain way to unlock the benefits.
To this end, our STRAT7 AI Champions have helped to build a set of ‘prompting guides’, which is readily available in strat7GPT and is being updated as we go along.
6. Rely on the wisdom of the crowds
Building strat7GPT has been a true team effort of Data Engineers, Data Scientists, Senior Leadership, Product Owners, InfoSec specialists and many other colleagues pulling together to build something that will add real, incremental value to the company.
This extends to moving from the current first stage to the next phases of strat7GPT too. We wanted to take on board as much user feedback as possible and feed this back into our roadmap. Relying too much on the product and development team’s judgment could risk making snap judgements on a limited sample of use cases.
7. Remember the importance of UX and UI testing
As a group with a track record of building market leading insight technology, we have incorporated the same testing frameworks with strat7GPT.
This means learning from how users naturally use the application and fixing the ‘small’ things that can quickly add up to deliver a better design, and more tactile user experience.
8. Use objective and subjective evaluation
While it can be tempting to leave the testing of a Generative AI models to the Data Scientists, we have used a hybrid approach to deciding which models (and model settings) to include.
Objectively, models can be tested by comparing their text outputs to the ‘ground truth’ (usually a human summary). For instance, we used an objective metric to test the accuracies of two models across 16 different model settings.
However, we have been keen to build a process where we don’t trust the objective results from these models in isolation. Through in-app feedback and UX/UI testing, we have built a process of learning from user’s subjective (but equally valuable) feedback before reserving judgement on where to go next on our journey with strat7GPT.
9. Put disclaimers up front
LLMs often hallucinate and make up results if they are not sure about their answers. While this can be mitigated via more powerful models, more specialised models or better prompting, we have been deliberately cautious.
For instance, when users load stat7GPT, they are met with a pop-up box which makes it clear that the results from the tool should not be taken at face value without human corroboration.
We have established strict rules about not copying and pasting outputs into emails and deliverables, especially when it comes to asking ‘factual’ questions in documents, where this information may be difficult to interpret or read for an AI model.
10. Consult and plan with the business
We have just finished our series of AI Possibility Sessions, consulting dozens of colleagues across the group on their needs, wants and wishes around the use of AI. This has helped to inform strat7GPT, as well as our roadmap for strat7.ai in the year ahead.
From these sessions, we overlaid an effort-reward framework to help prioritise the 100s of potential use cases down to a select few that can help to unlock new offers and services – and build on the initial success of strat7GPT.
So there you have it. We certainly learned a lot along the way!
We’re incredibly proud of the tool that we’ve created and we’re confident it will help to drive efficiencies across the STRAT7 group. Watch this space for more developments.